I’ve been looking for a job doing Rust development and one of the places I applied to was Vector, a DataDog acquisition in the observability space. Observability is one of those terms I had yet to encounter seriously before starting this search, so for the uninitiated:
…observability is the ability to measure a system’s current state based on the data it generates, such as logs, metrics, and traces.
– What is observability? | Dynatrace
Now, I didn’t get hired at Vector, but I did discover their product, which is an open source, programmable / configurable data pipeline tool. I’ll leave the explanation to them:
Vector is a high-performance observability data pipeline that enables you to collect, transform, and route all of your logs and metrics.
– Vector documentation
The vectordotdev/vector repo was several hundred thousand lines of Rust code. This was probably slightly more complex than my 100 loc CLI app. I was intrigued – would Rust’s type system hinder me? Would the compile times grind down my productivity? I wanted to see what it was like to do development on a real production application and get some additional Rust development under my belt, for personal and professional reasons. Thankfully, Vector being open source, I could do that.
Regarding contributing to open source: as someone who regularly finds employment in the tech industry, and is married to a working spouse with health insurance, I have a certain degree of privilege that affords me the time to contribute to open source. It’s important to acknowledge that open source is not a meritocracy and lack of open source contributions should not be considered a flaw in a candidate’s application. Working mothers, new entrants to the field, and people from under-represented groups have statistically less free time to make these kinds of contributions. Furthermore, as Ashe Dryden states in “The Ethics of Unpaid Labor and the OSS Community”, there are a few ways we can work to level the playing field for under-represented groups.
I got in touch with Jesse and Nathan on the Vector Discord channel via a former coworker (thanks Nathan Prime!). Jesse was kind enough to tell me about the company and the observability space over Zoom as well as point me to a few good first issues I could tackle on the vector repo and Nathan reviewed my code several times over the course of the month.
I decided to tackle issue #13329, adding a chunk method to the Vector Remap Language (VRL) stdlib.
Vector is essentially an ETL (Extract-Transform-Load) platform for shuffling data from one place to another (or in Vector lingo, from Sources to Sinks), and VRL is the domain language for transforming the data. If, for instance, you need to split, parse, or otherwise massage your logs before sending them to your data warehouse, VRL is the language a Vector user would do it in.
The rationale for the chunks method was that a Vector user had to send the transformed data to an API with a limitation of 1MB and wanted to be able to split the data into 1MB chunks.
I read a great article by the founder of HashiCorp, Mitchell Hashimoto, called “Contributing to Complex Projects” which was very insightful. The key ideas for me were to “become a user of the project” and “learn down, trace up.” The first is self explanatory. The second one was about tracing the execution path of a command down to the leaf nodes and then tracing the operations back up until you understand the entire path.
I highly recommend reading Hashimoto’s article, but not for the purposes of this blog post because I unfortunately disregarded its advice. I just dove right in and tried to grep my way out. I won’t elaborate that much on the journey, but little things like knowing that working on VRL means implementing a programming language might have helped me grok things a bit faster.
Adding the chunks() method is basically adding a global method to the standard library that Vector users can use in their VRL scripts. We can separate my pull request to the VRL stdlib into a few different pieces:
- Adding the method to the default features. I needed to do this first in order to get the unit tests to actually run:
- Implementing the function itself:
- Implementing the function metadata and various checks:
- The VRL function’s parameters
- VRL compile time errors and its associated test
- VRL fallibility constraints and its associated test – more on fallibility later
- Finally, documentation:
- Examples, which are essentially doctests
- chunks.cue, which is a CUE lang file for specifying Vector’s gorgeous documentation
It all came together a lot faster when Nathan suggested that I try out the REPL with cargo run vrl, then I could try to use the function in the terminal. It was a lot easier to understand – hence Hashimoto’s advice to become a user of the project. Just goes to show that you can lead a horse to water, but you can’t make it drink.
(Drinking is following directions. I’m the horse.)
Now, one of the reasons VRL is neat is because it makes fallibility a first class concept. If a function is determined to be fallible at compile time, you have to handle the error, much like unused_must_use in Rust. Somewhat confusingly, functions are not inherently fallible or infallible. The determination is made during the compilation process and depends on the inputs.
So for chunks(), which takes two parameters, a string and a chunk_size in bytes, we decided to make it infallible if the chunk_size parameter was a literal integer, and fallible otherwise, for instance it it was a method call.
So if you have a vrl program chunking a string into single byte chunks like so:
result = chunks("abcd", 1)
["a", "b", "c", "d"]This is infallible. The chunk_size of 1 is a literal integer, so the compilation process does not force the user to handle any errors.
Meanwhile, if you want a dynamic chunk_size, you get an error:
result = chunks("abcd", int!(floor(4.1)))
error[E103]: unhandled fallible assignment
┌─ :1:10
│
1 │ result = chunks("abcd", int!(floor(4.1)))
│ -------- ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
│ │ │
│ │ this expression is fallible
│ │ update the expression to be infallible
│ or change this to an infallible assignment:
│ result, err = chunks("abcd", int(floor(4.1)))
│
= see documentation about error handling at https://errors.vrl.dev/#handling
= learn more about error code 103 at https://errors.vrl.dev/103
= see language documentation at https://vrl.dev
= try your code in the VRL REPL, learn more at https://vrl.dev/examplesTo account for the fallibility, you must handle the error. Like Go, VRL has multiple return values, one for the value and one for the error:
result, err = chunks("abcd", int!(floor(4.1)))
"function call error for \"chunks\" at (14:46): function call error for \"int\" at (29:45): expected integer, got float"There’s currently a bit of tension between fallibility and compilation errors. For instance, we almost decided to make invalid inputs for chunk_size fallible, but went with making them compile time errors, instead. That way the user wouldn’t have to handle the fallibility and then additionally handle the error during runtime, the program just wouldn’t compile in the first place.
From a language ergonomics perspective, while I still enjoyed using Rust, the compile times did become painful. Compiling a debug version of vector from scratch took 7 minutes and 30 seconds. I later switched to using the mold linker and it went down to 6 minutes, but it was still disruptive. Meanwhile, a full release mode compile would take 14 minutes on my Core i9 iMac. Thankfully, incremental compiles were much quicker.
I also haven’t dug down into the root cause of the issue yet, but rust-analyzer did not do so well in this code base:
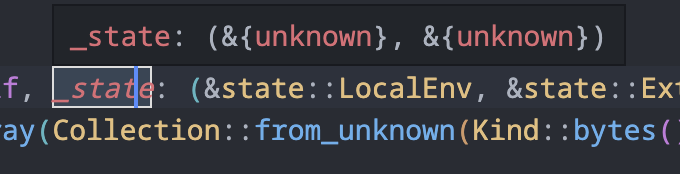
Between the unknown types and rust-analyzer spinning up the CPU fan on every change and establishing a file lock on the package cache that would block the compiler, I got off to a rough start.
For context, I didn’t really get Rust until I had rust-analyzer working. I had tried Rust a few times before without it or an IDE, and I felt like I was boxing the compiler blindfolded. I’d make a move only to be hammered with a novel type of compiler error with no real way to resolve it. Rust-analyzer’s in-editor hints and tight feedback loop really helped me understand the language. So rust-analyzer being less useful and even slowing down compilation was a big difference to my usual Rust workflow. I even turned off rust-analyzer for a bit to see if I got better and faster feedback from the compiler. Ultimately, I turned it back on, but it was painful getting used to the slow analysis and compilation speeds.
Ultimately, though, I still enjoyed programming in Rust – how can I get this chain of if let statements to look more readable without actually having if-let chains? How can I best use the type system to enforce the boundaries on valid inputs? Also the vector test harness, documentation system, and just working on a programming language (with its own type system) were very cool experiences.
So in conclusion, I just need a faster computer 😛
If this article inspired you to take a look at the Vector repo, Jesse also pointed me in the direction of this issue which is fairly similar to adding chunks() to the stdlib:
Add `zip` function to VRL · Issue #13104 · vectordotdev/vector
It should follow the same broad strokes as adding chunks(). Take a look and happy coding!
Additional Resources
In no particularly useful order:
- Vector Discord Channel
- Community | Vector
- feat(vrl): Adds `chunks` function by briankung · Pull Request #13794 · vectordotdev/vector
- Add `chunk` function to split up text into multiple pieces by size · Issue #13329 · vectordotdev/vector
- Add `zip` function to VRL · Issue #13104 · vectordotdev/vector
- Discovering Vector (2020)
- Vector Remap Language | Vector
- The Ethics of Unpaid Labor and the OSS Community | ashe dryden
Leave a Reply